


LinkedIn streeft ernaar om economische kansen te creëren voor elk lid van hun platform en meer. Om dit doel te bereiken willen ze de markt tussen kandidaat en vacature efficiënter maken. Het nieuwe Qualified Applicant AI-model van LinkedIn leert welke vaardigheden en ervaring een recruiter wenst op basis van gegevens van interacties van de recruiter met eerdere kandidaten. Sinds kort hebben ze hun succesmodel blootgelegd, in dit artikel wordt dit kort samengevat.
Het Qualified Applicant model
De waarschijnlijkheid van een positieve rekruteringsactie probeert LinkedIn te voorspellen. Maar een positieve rekrutering hangt vaak af van een specifieke context en kan dit verschillen bij elke recruiter en sollicitant. bijvoorbeeld kan dit inhouden dat een sollicitant wordt uitgenodigd voor een gesprek of dat hij of zij uiteindelijk een vacature krijgt aangeboden. Via personalisatie proberen ze deze acties te voorspellen. In kort kan je dus zeggen dat ze met behulp van globale patronen, gegevens van de sollicitant en gegevens van de recruiter/vacature een productervaring op maat kunnen creëren. Aangezien de LinkedIn-arbeidsmarkt groot en gevarieerd is, kan één enkel (globaal) machine learned model suboptimaal zijn om unieke eigenaardigheden vast te leggen.
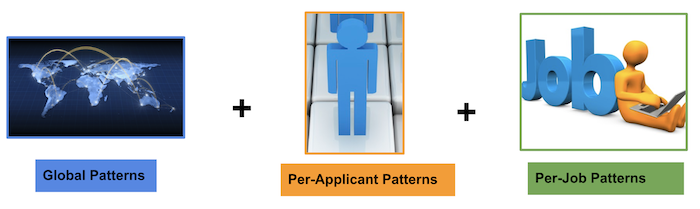
Deze drie componenten: globaal, per-kandidaaten en per-job worden in een lus getraind (met behulp van Photon ML en het volgende algoritme). Daarbij heeft een LinkedIn-analyse aangetoond dat de meerderheid van de sollicitanten op ten minste 5 banen solliciteert, terwijl de meerderheid van de vacatures ten minste 10 sollicitanten ontvangt. Dit resulteert in voldoende gegevens om de personalisatiemodellen te trainen.
Dagelijkse updates
High-velocity data modellen kunnen snel verouderen en moeten mogelijk vaak worden bijgeschoold. Dat geldt ook voor de personaliseringscomponenten van het QA-model, die worden getraind op het engagement van de recruiter. Bij de personalisatie van de per-jobmodellen gaat dit verval nog sneller. Frequente updates zijn dus cruciaal om de hoogst mogelijke prestatiewinst te behouden.
Om dit probleem op te lossen, heeft LinkedIn een fast approximate label collection pipeline geïmplementeerd. Ze verzamelen gegevens van alle negatieve en positieve feedback zodra deze beschikbaar is. De negatieve feedback wordt geregistreerd zodra er na 14 dagen geen engagement wordt gezien tussen sollicitant en rekruteer. Nieuwe labels genereren en deze in de QA te herschikking duurt ongeveer een dag, maar ze hopen dit proces in de toekomst te reduceren naar uren of zelfs enkele minuten.
Toepassingen en impact
Dit model wordt momenteel bij drie LinkedIn business branches ingezet: Job Seekers, Premium en Recruiter, en alle drie business lines zijn er aanzienlijke stijgingen van de cijfers waargenomen. Wil je een nog diepere analyse van het Qualified Applicant model bezoek dan zeker ook de blogpost van LinkedIn zelf.
















